Reference
Data Classes
Primary data classes:
|
Store multiple variables pertaining to a common set of measurement cases |
|
Container for categorial data. |
|
Container for scalar data. |
|
Container for n-dimensional data. |
|
|
Model classes (not usually initialized by themselves but through operations on primary data-objects):
|
Represents an Interaction effect. |
|
A list of effects. |
NDVar dimensions (not usually initialized by themselves but through
load functions):
|
Case dimension |
|
Simple categorial dimension |
|
Scalar dimension |
|
Dimension class for representing sensor information |
|
MNE surface-based source space |
|
MNE volume source space |
|
Represent multiple directions in space |
|
Dimension object for representing uniform time series |
File I/O
Eelbrain objects can be pickled. Eelbrain’s own pickle I/O functions provide backwards compatibility for pickled Eelbrain objects:
|
Pickle a Python object (see |
|
Load pickled Python objects from a file. |
|
Update FreeSurfer |
|
Load and re-save pickle files with a specific protocol |
Import
Functions and modules for loading specific file formats as Eelbrain object:
|
Load continuous neural data (CND) file used in the mTRF-Toolbox |
|
Load NIST SPH audio-files (uses sphfile |
|
Load a |
|
Load a wav file as NDVar |
Tools for loading data from the BESA-MN pipeline. |
|
Tools for importing data through mne. |
Export
Dataset with only univariate data can be saved as text using the
save_txt() method. Additional export functions:
|
Write any object that supports iteration to a text file |
|
Save an NDVar as wav file |
Sorting and Reordering
|
Align two data-objects based on index variables |
|
Align a data object to an index variable |
|
Divide y into cells defined by x. |
|
Combine data-objects picking from a different object for each case |
|
Combine a list of items of the same type into one item. |
|
Return an index to shuffle a data-object |
NDVar Initializers
|
Gaussian window |
|
Gaussian |
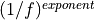 noise.
noise.NDVar Operations
NDVar objects support the native abs() and round()
functions. See also NDVar methods.
|
Butterworth filter |
|
Fill in missing vertices on an NDVar with a partial source space |
|
Concatenate multiple NDVars |
|
Convolve |
|
Correlation between two NDVars along a specific dimension |
|
Cross-correlation between two NDVars along the time axis |
|
Time frequency decomposition with Morlet wavelets (mne-python) |
|
Denoising source separation (DSS) |
|
Neural model for auditory edge-detection, as described by [1] and used in [2] |
|
Apply |
|
Find intervals from a boolean NDVar |
|
Find local maxima in an NDVar |
|
Frequency response for a FIR filter |
|
Gammatone filterbank response |
|
Convert labeled NDVar into a matrix operation to extract label values |
|
Create Labels from source space clusters |
|
Element-wise maximum of multiple array-like objects |
|
Element-wise minimum of multiple array-like objects |
|
Morph source estimate to a different MRI subject |
|
Normalize data in cells to make it appropriate for ANOVA [1] |
|
Calculate Neighbor correlation |
|
Pad (or crop) an NDVar in time |
|
Power spectral density with Welch's method |
|
Resample an NDVar along the time dimension |
|
Segment a continuous NDVar |
|
Change the adjacency of an NDVar or a Dimension |
|
Change the parcellation of an |
|
Crop and/or pad an |
|
Shift the time axis of an |
|
Project data from both hemispheres to |
Temporal Response Functions
|
Estimate a linear filter with coordinate descent |
|
Result from boosting |
|
Time series with one impulse for each of |
|
Time series with multiple impulses |
Tables
Manipulate data tables and compile information about data objects such as cell frequencies:
|
Create an NDVar by converting a data column to a dimension |
|
Subtract data in one cell from another |
|
Calculate frequency of occurrence of the categories in |
|
Restructure a Dataset such that a measured variable is in a single column |
|
Transform data to long format by converting an NDVar dimension into a variable |
|
Create a repeated-measures table |
|
Make a table with statistics |
Statistics
Univariate statistical tests:
|
Pearson product moment correlation between y and x |
|
Spearman rank correlation between y and x |
|
One-sample t-test |
|
Independent measures t-test |
|
Related-measures t-test |
|
Univariate ANOVA. |
|
Pairwise comparison table |
|
T-tests for one or more samples |
|
Correlation with one or more predictors |
|
Pairwise correlation table |
|
Mann-Whitney U-test (non-parametric independent measures test) |
|
Wilcoxon signed-rank test (non-parametric related measures test) |
|
Lilliefors' test for normal distribution |
Mass-Univariate Statistics
|
Mass-univariate one sample t-test |
|
Mass-univariate related samples t-test |
|
Mass-univariate independent samples t-test |
|
Mass-univariate contrast based on t-values |
|
Mass-univariate ANOVA |
|
Mass-univariate Pearson correlation significance test |
|
Test a vector field for vectors with non-random direction |
|
Test difference between two vector fields for non-random direction |
The tests in this module produce maps of statistical parameters, and implement different methods to compute corresponding maps of p-values that are corrected for multiple comparison:
- Permutation for maximum statistic (
samples=n) Compute
nparameter maps corresponding tonpermutations of the data. In each permutation, store the maximum value of the test statistic across the map. This is the distribution of the maximum parameter in a map under the null hypothesis. Then, calculate a p-value for each data point in the original parameter map based on where it lies in this distribution.- Threshold-based clusters [1] (
samples=n, pmin=p) Find clusters of data points where the original statistic exceeds a value corresponding to an uncorrected p-value of
p. For each cluster, calculate the sum of the statistic values that are part of the cluster (the cluster mass). Do the same innpermutations of the original data and retain for each permutation the value of the largest cluster. Evaluate all cluster values in the original data against the distributiom of maximum cluster values.- Threshold-free cluster enhancement [2] (
samples=n, tfce=True) Similar to permutation for maximum statstic, but each statistical parameter map is first processed with the cluster enhancement algorithm.
Two-stage tests
Two-stage tests proceed by estimating parameters for a fixed effects model for
each subject, and then testing hypotheses on these parameter estimates on the
group level. Two-stage tests are implemented by fitting an LM
for each subject, and then combining them in a LMGroup to
retrieve coefficients for group level statistics (see Two-stage test
example).
|
Fixed effects linear model |
|
Group level analysis for linear model |
References
Plotting
Plot univariate data (Var objects):
|
Barplot for a continuous variable |
|
Horizontal barplot for a continuous variable |
|
Boxplot for a continuous variable |
|
Legend for colors used in pairwise comparisons |
|
Scatter-plot |
|
Histogram plots with tests of normality |
|
Plot the regression of |
|
Plot a variable over time |
Color tools for plotting:
|
Automatically select colors for a categorial model |
|
Define colors for a single factor design |
|
Define cell colors for a two-way design |
|
Cross color with linestyle |
|
Generate an unambiguous color |
|
Soft-threshold a colormap to make small values transparent |
|
Colormap with 2 or 4 gradients (e.g., |
|
Plotting style for |
|
A color-bar for a matplotlib color-map |
|
Plot colors for a two-way design in a grid |
|
Plot colors with labels |
See also
Example with Eelbrain Colormaps
Plot uniform time-series:
|
Stack multiple lines vertically |
|
Value by time plot for uniform time series (UTS) data |
|
Plot statistics for a one-dimensional NDVar |
|
Save a movie combining multiple figures with moving time axes |
Plot multidimensional uniform time series:
|
Plot UTS data to a rectangular grid. |
|
Butterfly plot for NDVars |
Plot topographic maps of sensor space data:
|
Channel by sample plots with topomaps for individual time points |
|
Butterfly plot with corresponding topomaps |
|
Plot individual topogeraphies |
|
Topomaps in time-bins |
Plot sensor layout maps:
|
Plot sensor positions in 2 dimensions |
|
Multiple views on a sensor layout. |
|
Plot sensor positions in 3 dimensions |
Method related plots:
|
Preview how data will be partitioned for the boosting function |
|
xax parameter
Many plots have an xax parameter which is used to sort the data in y
into different categories and plot them on separate axes. xax can be
specified through categorial data, or as a dimension in y.
If a categorial data object is specified for xax, y is split into the
categories in xax, and for every cell in xax a separate subplot is
shown. For example, while
>>> plot.Butterfly('meg', data=data)
will create a single Butterfly plot of the average response,
>>> plot.Butterfly('meg', 'subject', data=data)
where 'subject' is the xax parameter, will create a separate subplot
for every subject with its average response.
A dimension on y can be specified through a string starting with ..
For example, to plot each case of meg separately, use:
>>> plot.Butterfly('meg', '.case', data=data)
General layout parameters
Most plots that also share certain layout keyword arguments. By default, all those parameters are determined automatically, but individual values can be specified manually by supplying them as keyword arguments.
h,wscalarHeight and width of the figure. Use a number ≤ 0 to defined the size relative to the screen (e.g.,
w=0to use the full screen width).axh,axwscalarHeight and width of the axes.
rows,columnsNone|intLimit the number of rows or columns of axes in the figure. If neither is specified, a square layout is produced.
marginsdictAbsolute subplot parameters (in inches). Implies
tight=False. Ifmarginsis specified,axwandaxhare interpreted exclusive of the margins, i.e.,axh=2, margins={'top': .5}for a plot with one axes will result in a total height of 2.5. Example:margins={ 'top': 0.5, # from top of figure to top axes 'bottom': 1, # from bottom of figure to bottom axes 'hspace': 0.1, # height of space between axes 'left': 0.5, # from left of figure to left-most axes 'right': 0.1, # from right of figure to right-most axes 'wspace': 0.1, # width of space between axes }
ax_aspectscalarWidth / height aspect of the axes.
framebool|strHow to frame the axes of the plot. Options:
True(default): normal matplotlib frame, spines around axesFalse: omit top and right spines't': draw spines at x=0 and y=0, common for ERPs'none': no spines at all
namestrWindow title (not displayed on the figure itself).
titlestrFigure title (displayed on the figure).
tightboolUse matplotlib’s
tight_layoutto resize all axes to fill the figure.right_ofeelbrain plotPosition the new figure to the right of this figure.
beloweelbrain plotPosition the new figure below this figure.
Plots that do take those parameters can be identified by the **layout in
their function signature.
Helper functions
|
Specify |
|
Draw the outline of the current figure |
GUI Interaction
By default, new plots are automatically shown and, if the Python interpreter is in interactive mode the GUI main loop is started. This behavior can be controlled with 2 arguments when constructing a plot:
- showbool
Show the figure in the GUI (default True). Use False for creating figures and saving them without displaying them on the screen.
- runbool
Run the Eelbrain GUI app (default is True for interactive plotting and False in scripts).
The behavior can also be changed globally using configure().
By default, Eelbrain plots open in windows with enhance GUI features such as
copying a figure to the OS clip-board. To plot figures in bare matplotlib
windows, configure() Eelbrain with eelbrain.configure(frame=False).
Plotting Brains
The plot.brain module contains specialized functions to plot
NDVar objects containing source space data.
For this it uses a subclass of PySurfer’s surfer.Brain class.
The functions below allow quick plotting.
More specific control over the plots can be achieved through the
Brain object that is returned.
|
Create a |
|
Shortcut for a Butterfly-plot with a time-linked brain plot |
|
Plot a spatio-temporal cluster |
|
Plot a source estimate with coloring for dSPM values (bipolar). |
|
Plot a map of p-values in source space. |
|
Plot the parcellation in an annotation file |
|
Plot a legend for a freesurfer parcellation |
|
PySurfer |
|
Grid of anatomical images in one figure |
|
Plot 2d projections of a brain volume |
|
Shortcut for a butterfly-plot with a time-linked glassbrain plot |
In order to make custom plots, a Brain figure
without any data added can be created with
plot.brain.brain(ndvar.source, mask=False).
Surface options for plotting data on fsaverage:
white
|
smoothwm
|
inflated_pre
|
inflated
|
inflated_avg
|
sphere
|



GUIs
Tools with a graphical user interface (GUI):
|
GUI for selecting ICA-components |
|
GUI for rejecting trials of MEG/EEG data |
GUI for detecting and loading source estimates |
Controlling the GUI Application
When Eelbrain is used in a terminal (as opposed to, from a notebook), Eelbrain creates a wxPython application for graphical user interfaces (GUIs). This application appears as a separate icon in the Dock. How to control this application depends on the environment from which it is invoked.
When Eelbrain plots are created from within iPython, the GUI is managed in the
background and control returns immediately to the terminal. There might be cases
in which this is not desired, for example when running scripts. After execution
of a script finishes, the interpreter is terminated and all associated plots are
closed. To avoid this, the command gui.run(block=True) can be inserted at
the end of the script, which will keep all gui elements open until the user
quits the GUI application (see gui.run() below).
In interpreters other than iPython, input can not be processed from the GUI
and the interpreter shell at the same time. In that case, the GUI application
is activated by default whenever a GUI is created in interactive mode
(this can be avoided by passing run=False to any plotting function).
While the application is processing user input,
the shell can not be used. In order to return to the shell, quit the
application (the python/Quit Eelbrain menu command or Command-Q). In order to
return to the terminal without closing all windows, use the alternative
Go/Yield to Terminal command (Command-Alt-Q). To return to the application
from the shell, run gui.run(). Beware that if you terminate the Python
session from the terminal, the application is not given a chance to assure that
information in open windows is saved.
|
Hand over command to the GUI (quit the GUI to return to the terminal) |
Reports
The report submodule contains shortcuts for producing data summaries and
visualizations. Meant to work in Jupyter notebooks.
|
Table with pairwise scatter-plots (see |
Formatted Text
The fmtxt submodule provides elements and tools for reports. Most eelbrain
functions and methods that print tables in fact return fmtxt objects,
which can be exported in different formats, for example:
>>> data = datasets.get_uts()
>>> table.stats('Y', 'A', 'B', data=data)
B
---------------
b0 b1
--------------------
a0 0.8857 0.4525
a1 0.3425 1.377
>>> type(table.stats('Y', 'A', 'B', data=data))
eelbrain.fmtxt.Table
This means that the result can be exported as formatted text, for example:
>>> fmtxt.save_pdf(table.stats('Y', 'A', 'B', data=data))
See available export functions in the module documentation:
Document model for formatted text documents |
Experiment Pipeline
The MneExperiment class provides a template for analyzing EEG and MEG
data. The objects for specifying the analysis are all in the
pipeline submodule.
See also
For the guide on working with the MneExperiment class see
The MneExperiment Pipeline.
|
Analyze an MEG or EEG experiment |
Result containers:
|
Test results for temporal tests in one or more ROIs |
|
Test results for 2-stage tests in one or more ROIs |
Participant groups:
|
Group defined as collection of subjects |
|
Group defined by removing subjects from a base group |
Pre-processing:
|
Raw data source |
|
Filter raw pipe |
|
ICA raw pipe |
|
Maxwell filter raw pipe |
|
Oversampled temporal projection: see |
|
Re-reference EEG data |
|
Apply ICA estimated in a |
Event variables:
|
Variable based on evaluating a statement |
|
Group membership for each subject |
|
Variable assigning labels to values |
Epochs:
|
Epoch based on selecting events from a raw file |
|
Epoch inheriting events from another epoch |
|
Combine several other epochs |
Tests:
|
ANOVA test |
|
One-sample t-test |
|
Independent measures t-test (comparing groups of subjects) |
|
Related measures t-test |
|
Contrasts of T-maps (see |
|
Two-stage test: T-test of regression coefficients |
Brain parcellations:
|
A subset of labels in another parcellation |
|
Recombine labels from an existing parcellation |
|
Parcellation that is created outside Eelbrain for each subject |
|
Fsaverage parcellation that is morphed to individual subjects |
|
Parcellation that is grown from seed coordinates |
|
Seed parcellation with individual seeds for each subject |
Datasets
Datasets for experimenting and testing:
Dataset used for illustration purposes by Loftus and Masson (1994) |
|
|
Load events and epochs from the MNE sample data |
|
Create a sample Dataset with 60 cases and random data. |
|
Dataset with random univariate data |
|
Simulate event-related EEG data |
Configuration
- eelbrain.configure(n_workers=None, frame=None, autorun=None, show=None, format=None, figure_background=None, prompt_toolkit=None, animate=None, nice=None, tqdm=None, log=None)
Set basic configuration parameters for the current session
- Parameters:
n_workers (bool | int) – Number of worker processes to use in multiprocessing enabled computations.
Falseto disable multiprocessing.True(default) to use as many processes as cores are available. Negative numbers to use all but n available CPUs.frame (bool) – Open figures in the Eelbrain application. This provides additional functionality such as copying a figure to the clipboard. If False, open figures as normal matplotlib figures.
autorun (bool) – When a figure is created, automatically enter the GUI mainloop. By default, this is True when the figure is created in interactive mode but False when the figure is created in a script (in order to run the GUI at a specific point in a script, call
eelbrain.gui.run()).show (bool) – Show plots on the screen when they’re created (disable this to create plots and save them without showing them on the screen).
format (str) – Default format for plots (for example “png”, “svg”, …).
figure_background (bool | matplotlib color) – While
matplotlibuses a gray figure background by default, Eelbrain uses white. Set this parameter toFalseto use the default frommatplotlib.rcParams, or set it to a valid matplotblib color value to use an arbitrary color.Trueto revert to the default white.prompt_toolkit (Literal[False, 'eelbrain', 'wx']) – In IPython 5, prompt_toolkit allows running the GUI main loop in parallel to the Terminal, meaning that the IPython terminal and GUI windows can be used without explicitly switching between Terminal and GUI. Set to
'eelbrain'to use the Eelbrain-specific GUI loop (default);'wx'to use iPython’s GUI loop;Falseto block the terminal instead (can be more stable when using GUIs).animate (bool) – Animate plot navigation (default True).
nice (int [-20, 19]) – Scheduling priority for muliprocessing (larger number yields more to other processes; negative numbers require root privileges).
tqdm (bool) – Enable or disable
tqdmprogress bars.log (bool) – Enable logging (for debugging Eelbrain).