Note
Go to the end to download the full example code.
ANCOVA
Analysis of covariance for univariate data.
Example 1
Based on [1], Exercises (page 8).
Show the model
intercept Hours Genotype Hours x Genotype
-----------------------------------------------------------------------------
1 8 1 0 0 0 0 8 0 0 0 0
1 12 1 0 0 0 0 12 0 0 0 0
1 16 1 0 0 0 0 16 0 0 0 0
1 24 1 0 0 0 0 24 0 0 0 0
1 8 0 1 0 0 0 0 8 0 0 0
1 12 0 1 0 0 0 0 12 0 0 0
1 16 0 1 0 0 0 0 16 0 0 0
1 24 0 1 0 0 0 0 24 0 0 0
1 8 0 0 1 0 0 0 0 8 0 0
1 12 0 0 1 0 0 0 0 12 0 0
1 16 0 0 1 0 0 0 0 16 0 0
1 24 0 0 1 0 0 0 0 24 0 0
1 8 0 0 0 1 0 0 0 0 8 0
1 12 0 0 0 1 0 0 0 0 12 0
1 16 0 0 0 1 0 0 0 0 16 0
1 24 0 0 0 1 0 0 0 0 24 0
1 8 0 0 0 0 1 0 0 0 0 8
1 12 0 0 0 0 1 0 0 0 0 12
1 16 0 0 0 0 1 0 0 0 0 16
1 24 0 0 0 0 1 0 0 0 0 24
1 8 0 0 0 0 0 0 0 0 0 0
1 12 0 0 0 0 0 0 0 0 0 0
1 16 0 0 0 0 0 0 0 0 0 0
1 24 0 0 0 0 0 0 0 0 0 0
Estimate the ANCOVA:
Plot the slopes:
p = plot.Regression(y, hours, genotype)
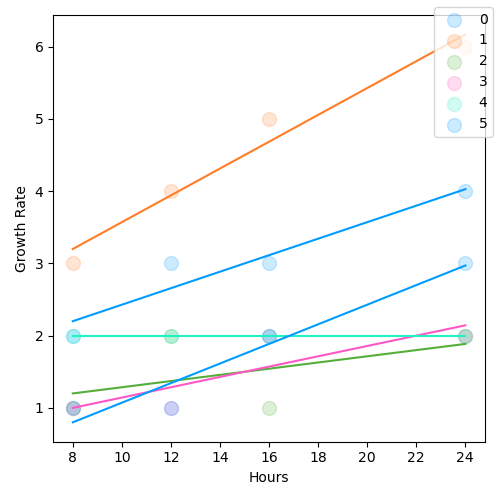
Example 2
Based on [2] (p. 118-20)
Full model, with interaction
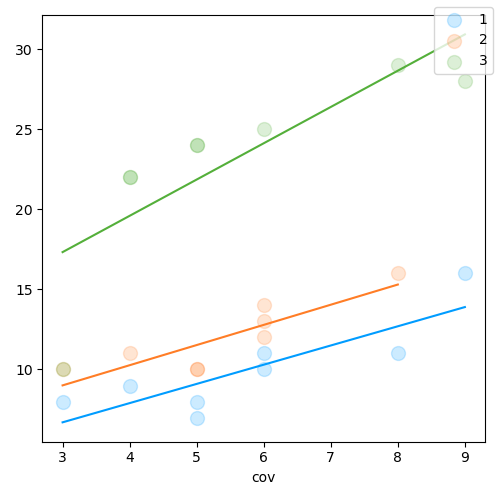
Drop interaction term
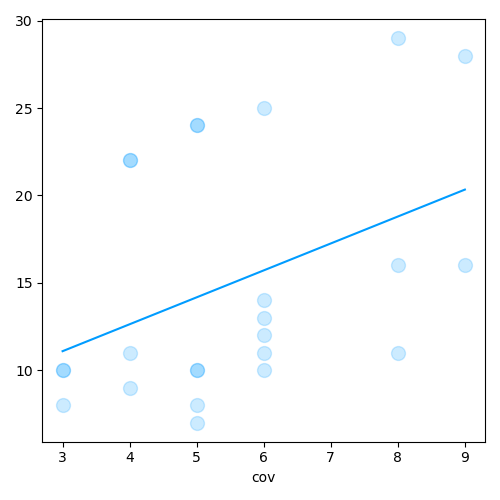
ANCOVA with multiple covariates
Based on [3], p. 139.
# Variable summary
ds.summary()