Note
Go to the end to download the full example code.
Introduction
Data are represented with three primary data-objects:
Factorfor categorial variablesVarfor scalar variablesNDVarfor multidimensional data (e.g. a variable measured at different time points)
Multiple variables belonging to the same dataset can be grouped in a
Dataset object.
Factor
A Factor is a container for one-dimensional, categorial data: Each
case is described by a string label. The most obvious way to initialize a
Factor is a list of strings:
Factor(['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b'], name='A')
Since Factor initialization simply iterates over the given data, the same Factor could be initialized with:
Factor(['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b'], name='A')
There are other shortcuts to initialize factors (see also
the Factor class documentation):
Factor(['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'c', 'c', 'c', 'c'], name='A')
Indexing works like for arrays:
a[0]
'a'
a[0:6]
Factor(['a', 'a', 'a', 'a', 'b', 'b'], name='A')
All values present in a Factor are accessible in its
Factor.cells attribute:
a.cells
('a', 'b', 'c')
Based on the Factor’s cell values, boolean indexes can be generated:
a == 'a'
array([ True, True, True, True, False, False, False, False, False,
False, False, False])
a.isany('a', 'b')
array([ True, True, True, True, True, True, True, True, False,
False, False, False])
a.isnot('a', 'b')
array([False, False, False, False, False, False, False, False, True,
True, True, True])
Interaction effects can be constructed from multiple factors with the %
operator:
Factor(['d', 'd', 'e', 'e', 'd', 'd', 'e', 'e', 'd', 'd', 'e', 'e'], name='B')
A % B
Interaction effects are in many ways interchangeable with factors in places where a categorial model is required:
(('a', 'd'), ('a', 'e'), ('b', 'd'), ('b', 'e'), ('c', 'd'), ('c', 'e'))
i == ('a', 'd')
array([ True, True, False, False, False, False, False, False, False,
False, False, False])
Var
The Var class is a container for one-dimensional
numpy.ndarray:
Var([1, 2, 3, 4, 5, 6])
Indexing works as for factors
y[5]
6
y[2:]
Var([3, 4, 5, 6])
Many array operations can be performed on the object directly
y + 1
Var([2, 3, 4, 5, 6, 7])
For any more complex operations the corresponding numpy.ndarray
can be retrieved in the Var.x attribute:
array([1, 2, 3, 4, 5, 6])
Note
The Var.x attribute is not intended to be replaced; rather, a new
Var object should be created for a new array.
NDVar
NDVar objects are containers for multidimensional data, and manage the
description of the dimensions along with the data. NDVar objects are
usually constructed automatically by an importer function (see
File I/O), for example by importing data from MNE-Python through
load.mne.
Here we use data from a simulated EEG experiment as example:
<NDVar 'eeg': 80 case, 140 time, 65 sensor>
This representation shows that eeg contains 80 trials of data (cases),
with 140 time points and 35 EEG sensors.
The object provides access to the underlying array…
array([[[-9.50111788e-08, -1.04642705e-06, 1.16673003e-06, ...,
-5.28298832e-07, -2.16915231e-06, -1.15400897e-06],
[ 8.88330456e-07, -1.70334042e-06, 4.79180941e-08, ...,
-1.50933527e-06, -5.23096550e-06, -1.27798437e-06],
[ 1.94946162e-06, -2.38294931e-06, -1.41702756e-06, ...,
-2.21301091e-06, -2.92643448e-06, -1.52872560e-06],
...,
[ 1.00206507e-06, -2.32746836e-06, -1.33991608e-06, ...,
-7.02062901e-07, -4.06153310e-07, -9.58134307e-07],
[ 4.02001414e-07, -2.28908191e-06, -1.79700456e-06, ...,
1.36511189e-07, -1.45611850e-06, 9.34552296e-07],
[ 7.69075193e-07, -2.32175131e-06, -6.91790357e-07, ...,
1.90843413e-06, -1.82126693e-06, 2.52864415e-06]],
[[ 6.81837210e-07, 6.65419804e-07, 1.12320370e-06, ...,
-4.09914843e-06, -4.39193509e-07, -5.80747494e-06],
[ 1.61595534e-06, 9.55153828e-07, 1.22640000e-06, ...,
-2.06395553e-06, 1.79426510e-06, -3.04768526e-06],
[ 3.12237561e-06, 6.38998912e-07, -3.00981448e-07, ...,
-2.43531876e-06, -7.51251176e-07, -3.35157500e-06],
...,
[ 2.39355975e-07, 2.03071119e-06, 1.63262922e-06, ...,
1.73190284e-06, 1.79773187e-06, 3.85666860e-09],
[-1.85084893e-07, -1.41108516e-07, 9.19784815e-07, ...,
1.29478270e-06, -2.07274571e-06, 2.69513509e-07],
[-2.43341124e-07, 7.31243067e-07, 5.03500017e-08, ...,
-4.79479260e-07, 5.59408940e-07, -1.07537824e-06]],
[[-4.91713772e-07, 1.82896084e-06, -4.90818719e-07, ...,
2.04898709e-06, 8.07954601e-07, 2.40001527e-06],
[-6.35812838e-07, 2.34737429e-06, -1.69700744e-07, ...,
2.22999637e-06, -6.90795389e-08, 2.00187872e-06],
[-1.36326852e-06, 2.15356560e-06, -7.90944827e-07, ...,
1.20470921e-07, -1.51992420e-07, 4.99762488e-07],
...,
[-2.09568176e-06, -8.26343851e-07, -2.05615771e-06, ...,
4.21620683e-06, 2.36786102e-06, 3.99403992e-06],
[-9.39885725e-07, -4.15705678e-07, -1.25085583e-06, ...,
4.18212307e-06, -8.14217732e-07, 4.22833819e-06],
[-1.24441185e-06, -3.58295830e-07, -1.50557329e-06, ...,
3.06174222e-06, -1.06560328e-06, 4.15404587e-06]],
...,
[[-1.60593392e-06, 2.93152290e-07, 3.49658602e-07, ...,
-2.46201079e-06, 7.42394736e-08, -5.04382865e-06],
[-1.07739478e-06, 9.51648194e-07, 1.82585823e-06, ...,
-5.76078835e-08, 8.96132283e-07, -2.28870369e-06],
[-5.18263189e-07, -8.84020766e-07, -8.52374561e-07, ...,
1.02763807e-06, 3.87745625e-06, -1.25615047e-06],
...,
[-2.33322126e-06, -1.09573817e-06, -2.84218705e-07, ...,
2.20821782e-06, 6.61850616e-06, 7.65102960e-07],
[-1.61853508e-06, -2.95451764e-06, -2.53204668e-07, ...,
2.97702225e-06, 9.71002878e-07, 1.19720572e-06],
[-4.70300767e-07, -1.39830386e-06, -9.39008791e-07, ...,
1.53713337e-06, 3.67539734e-06, -4.63646929e-07]],
[[-2.23188921e-06, -5.53575294e-07, -5.61720436e-07, ...,
1.20602456e-06, 9.26045216e-07, 3.99046377e-07],
[ 7.23235664e-07, 1.16854425e-06, 1.89504163e-06, ...,
-1.58990898e-07, 2.61973485e-07, -5.51795289e-07],
[ 1.75835425e-06, 2.55172906e-06, 1.60883687e-06, ...,
9.85042655e-07, -1.77151943e-06, 6.56482036e-07],
...,
[ 9.91921731e-07, 3.10452857e-06, 3.39830446e-06, ...,
-1.45126771e-06, 1.03441586e-06, -2.36748667e-06],
[-3.13784881e-07, 2.31238548e-06, 8.37155635e-07, ...,
2.50922771e-07, -8.73274595e-08, 2.27469055e-07],
[ 5.34066660e-07, 2.87363293e-06, 1.56710643e-06, ...,
-1.28120965e-06, -5.36171343e-07, -2.34311739e-06]],
[[-9.36723413e-07, 1.45112052e-06, 7.65945152e-07, ...,
3.76035169e-06, 1.54461182e-06, 4.22766145e-06],
[-1.47092562e-06, 8.27823105e-07, 4.30722536e-07, ...,
4.34952441e-06, 3.02232985e-06, 6.46300663e-06],
[-5.08363053e-07, 1.77742743e-07, -3.90413438e-07, ...,
3.79157418e-06, 2.91690585e-06, 4.85980962e-06],
...,
[ 8.88693695e-07, 9.43715823e-07, 7.70657794e-07, ...,
2.37240888e-06, 2.33647167e-06, 4.32167153e-06],
[-8.39577857e-07, -1.14923274e-06, -9.68268476e-07, ...,
3.98016557e-06, 4.43879119e-06, 4.25379038e-06],
[-2.50745698e-06, -5.53859780e-07, -1.39923439e-06, ...,
4.70581546e-06, 1.36900230e-06, 4.36907433e-06]]])
… and dimension descriptions:
<Sensor n=65, name='standard_alphabetic'>
UTS(-0.1, 0.005, 140)
Eelbrain functions take advantage of the dimensions descriptions (such as sensor locations), for example for plotting:
p = plot.TopoButterfly(eeg, t=0.130)
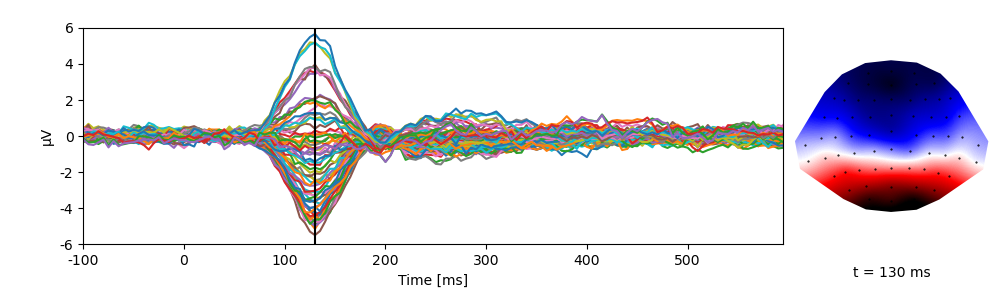
NDVar offer functionality similar to numpy.ndarray, but
take into account the properties of the dimensions. For example, through the
NDVar.sub() method, indexing can be done using meaningful descriptions,
such as indexing a time slice in seconds …
<NDVar 'eeg': 80 case, 65 sensor>
… or extracting data from a specific sensor:
<NDVar 'eeg': 80 case, 140 time>
Other methods allow aggregating data, for example an RMS over sensor …
eeg_rms = eeg.rms('sensor')
plot.UTSStat(eeg_rms)
eeg_rms
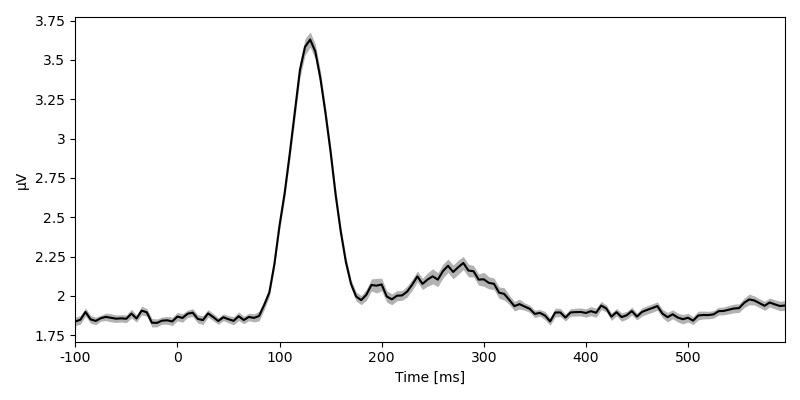
<NDVar 'eeg': 80 case, 140 time>
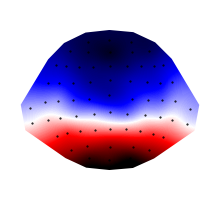
… or a mean in a time window:
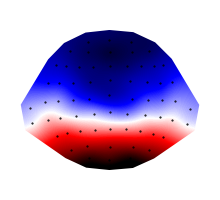
eeg_average = eeg.mean(time=(0.100, 0.150))
p = plot.Topomap(eeg_average)
Dataset
A Dataset is a container for multiple variables
(Factor, Var and NDVar) that describe the same
cases. It can be thought of as a data table with columns corresponding to
different variables and rows to different cases.
Consider the dataset containing the simulated EEG data used above:
Because this can be more output than needed, the
Dataset.head() method only shows the first couple of rows:
This dataset containes severeal univariate columns: cloze, predictability, and n_chars.
The last line also indicates that the dataset contains an NDVar called eeg.
The NDVar is not displayed as column because it contains many values per row.
In the NDVar, the Case dimension corresponds to the row in the dataset
(which here corresponds to simulated trial number):
data['eeg']
<NDVar 'eeg': 80 case, 140 time, 65 sensor>
The type and value range of each entry in the Dataset can be shown using the Dataset.summary() method:
An even shorter summary can be generated by the string representation:
repr(data)
"<Dataset (80 cases) 'eeg':Vnd, 'cloze':V, 'predictability':F, 'n_chars':V>"
Here, 80 cases indicates that the Dataset contains 80 rows. The
subsequent dictionary-like representation shows the keys and the types of the
corresponding values (F: Factor, V: Var, Vnd: NDVar).
Datasets can be indexed with columnn names, …
data['cloze']
Var([0.0261388, 0.995292, 0.930622, 0.824039, 0.170413, 0.18508, 0.233447, 0.807838, 0.249786, 0.267532, 0.193768, 0.131276, 0.115032, 0.124399, 0.947853, 0.17053, 0.848885, 0.204546, 0.214557, 0.89373, 0.234159, 0.859228, 0.239748, 0.823746, 0.825785, 0.920969, 0.191976, 0.934128, 0.138444, 0.156554, 0.81922, 0.933353, 0.967589, 0.127096, 0.822075, 0.995352, 0.863086, 0.872742, 0.043006, 0.832262, 0.23227, 0.850658, 0.289099, 0.820409, 0.997675, 0.964199, 0.00563694, 0.831794, 0.163465, 0.839316, 0.0354823, 0.0793667, 0.277679, 0.871902, 0.827637, 0.939526, 0.856561, 0.261004, 0.283124, 0.164644, 0.841775, 0.136845, 0.00606552, 0.88772, 0.180829, 0.158668, 0.812045, 0.237518, 0.183629, 0.873745, 0.893262, 0.887406, 0.0213108, 0.283401, 0.914039, 0.293586, 0.842077, 0.81942, 0.185291, 0.931266], name='cloze')
… row numbers, …
data[2:5]
… or both, in wich case row comes before column:
data[2:5, 'n_chars']
Var([3, 7, 4], name='n_chars')
Array-based indexing also allows indexing based on the Dataset’s variables:
data['n_chars'] == 3
array([False, False, True, False, False, False, False, True, False,
False, False, False, True, False, False, False, False, True,
False, False, False, False, False, False, True, False, False,
False, True, False, True, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, True, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
True, True, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False])
Dataset.eval() allows evaluatuing code strings in the namespace
defined by the dataset, which means that dataset variables can be invoked
with just their name:
data.eval("predictability == 'high'")
array([False, True, True, True, False, False, False, True, False,
False, False, False, False, False, True, False, True, False,
False, True, False, True, False, True, True, True, False,
True, False, False, True, True, True, False, True, True,
True, True, False, True, False, True, False, True, True,
True, False, True, False, True, False, False, False, True,
True, True, True, False, False, False, True, False, False,
True, False, False, True, False, False, True, True, True,
False, False, True, False, True, True, False, True])
Many dataset methods allow using code strings as shortcuts for expressions involving dataset variables, for example indexing:
data.sub("predictability == 'high'").head()
Columns in the Dataset can be used to define models, for statistics,
aggregating and plotting.
Any string specified as argument in those functions will be evaluated in the
dataset, thuse, because we can use:
data.eval("eeg.sub(sensor='Cz')")
<NDVar 'eeg': 80 case, 140 time>
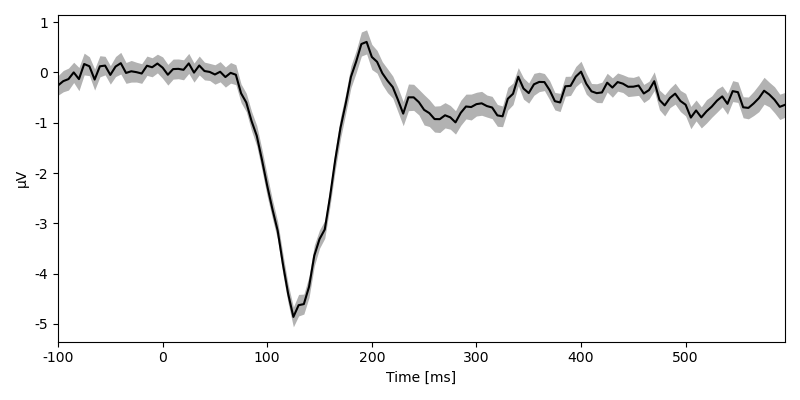
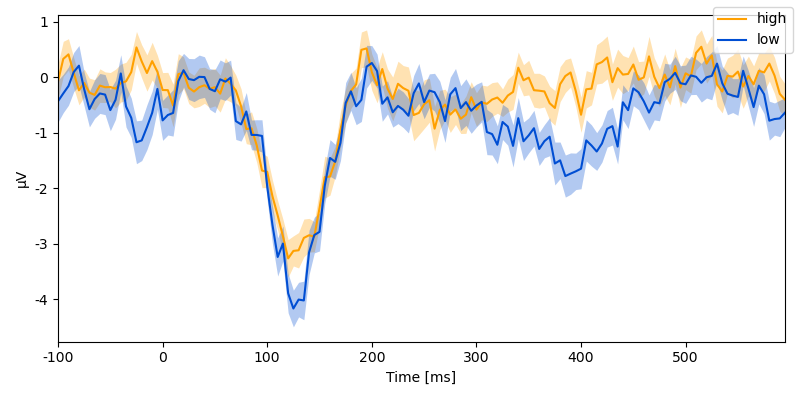
… we can quickly plot the time course of a sensor by condition:
p = plot.UTSStat("eeg.sub(sensor='Cz')", "predictability", data=data)
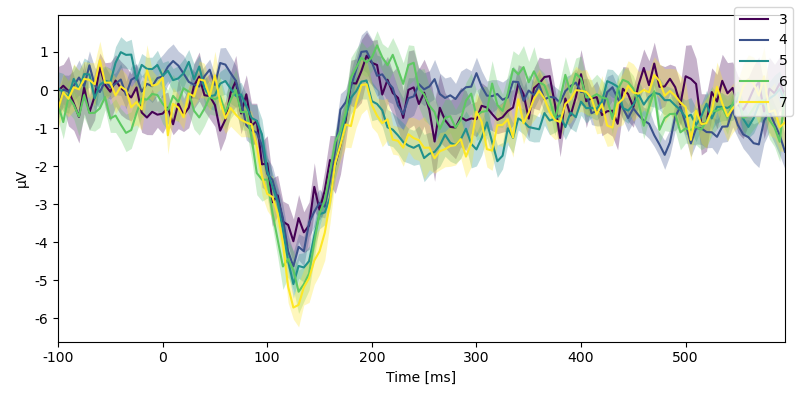
p = plot.UTSStat("eeg.sub(sensor='Fz')", "n_chars", data=data, colors='viridis')
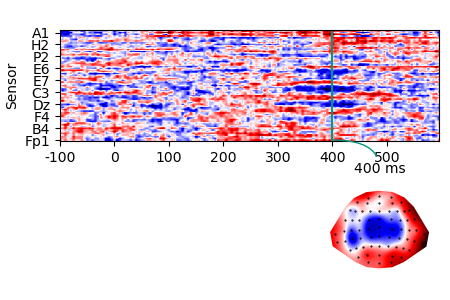
Or calculate a difference wave:
data_average = data.aggregate('predictability')
data_average
difference = data_average[1, 'eeg'] - data_average[0, 'eeg']
p = plot.TopoArray(difference, t=[None, None, 0.400])
For examples of how to construct datasets from scratch see Dataset basics.